The story below details a very interesting & transformational project that I was a part of in 2014 and 2015, at a Dutch company. I’ve told this story before during a number of conference talks (slides and videos are available, if you’re interested), and I’ve now finally come around to writing it up as a series of blog posts!
This is part 2 of a multipart series on how CD, DevOps, and other principles were used to overhaul an existing software application powering multiple online job boards, during a project at a large company in The Netherlands.
In the previous installment, I discussed the background of the project, and the central question put forth from the issues and goals: do we buy or build? And if we build, in what way?
Strangulation
As I discussed in part 1, a cut-over rewrite is not only risky, it ends up rebuilding all sorts of unneeded functionality, because it’s hard to determine what’s needed or not needed.
The answer then lies not in such a “go-for-broke” rewrite, but rather in an approach that significantly reduces risk: strangling the existing application with a new system. Coined and described by Martin Fowler in his Strangler Application article (https://www.martinfowler.com/bliki/StranglerApplication.html), this pattern is all about iteratively building value (in short cycles, with frequent releases), and incrementally moving functionality from the old to the new system.
For this particular case, we took the opportunity to split the existing monolithic applications into smaller components. Specifically, it meant moving towards a service landscape, consisting of services oriented around the key domain objects: Job Seeker, Job, CV, etc. Each of these services should be independently deployable, with its own build/deployment pipeline and run as a Docker container (more on that later).
We then added a simple proxy, which decides where incoming web traffic should be routed: to one of these services, or to the legacy monolith. How we applied this pattern in this particular situation is discussed in much more detail in https://www.michielrook.nl/2016/11/strangler-pattern-practice/.
API-first
Next to the online job board, the application exposed a number of API endpoints that could be used by recruiters and organizations to (automatically) add vacancies and search for candidates, from their own ERP or hiring / recruitment systems.
The problem was, those API’s were never first-class citizens, because they were not used internally, considered very important nor sufficiently tested. This had a detrimental effect on the quality, stability and usability of the API’s in question. To improve the API’s on all those levels, we tried to install a principle where every API that we expose to the outside world is consumed internally as well.
Improvement!
So, now that we defined an architecture, and we have a strategy to strangle our existing application, it’s time to start thinking about our way of working and structure. Next to that, we discussed & collaborated together on the ground rules and patterns for all the new code we would write.
At the time, the organization was already well on its way to transitioning to an Agile way of working. Product-oriented development, rather than waterfall-esque projects. We realized that, to be successful, we needed to move to a development model where stable teams would apply short cycles and fast feedback to continuously innovate and develop a product.
To make that mindset possible from a technical point of view, we wanted to apply the principles of Continuous Integration, Continuous Delivery and Continuous Deployment: the Continuous Everything methodology.
This CD thing
I wrote about the progression from continuous integration to continuous delivery, and finally to continuous deployment in this article: https://www.michielrook.nl/2016/07/continuous-delivery-continuous-deployment/
My personal view is that such a pipeline should finish in less than 15 minutes; measured from the moment a developer checks in code, to the artifact fully rolled out to production. There are differing views on this of course, and it depends on the programming language, infrastructure used, scale and other constraints.
A fast pipeline, testing changes and then deploying them to production in minutes, is very important to have fast & early feedback, which helps to validate those changes.
One key consequence of such a pipeline is that, as long as all the tests and other verifications pass, every commit goes to production. This has significant implications on the way of working of a development team.
Every commit goes to production
A fast pipeline encourages short cycles, small steps & commits, and greatly reduces the cost of experimentation.
On branches
A lot has been said, discussed and written about the usefulness (or lack thereof) of using branches in version control systems.
I’m a big proponent of a development model (or style) called Trunk Based Development. Adopting this model means one’s changes are only committed to the main line of development, so branches are (in principle) not used. Possibly controversial, but there it is. Earlier, I wrote some of my thoughts regarding branches in an article here.
Trunk Based Development is not a new pattern. I believe that branching has become much more popular in recent times due to tools such as Git and Mercurial, and platforms such as GitHub and GitLab, which make branching a cheap and simple operation. In the days of Subversion (or even CVS), branching and especially merging was an expensive and often painful process.
Note: in some contexts, such as software that actually physically ships, it could be acceptable to create a branch for every release version that will be pushed. For more details on this branching model, refer to https://trunkbaseddevelopment.com/branch-for-release/
Note #2: some teams successfully use short-lived feature branches. I’m not a big fan, to be honest. Continuous Integration and Extreme Programming principles suggest team members (or pairs) integrate their work with that of the rest of the team at least daily. This implies a branch age of less than a day, in which case the usefulness of using branches at all diminishes in my view.
Feature toggles
Sometimes, (features) branches are used to control when functionality is released, by merging a specific branch to master when a certain threshold or date has been met. To some degrees though, that’s abusing version control for functional separation. Deploying software is (or should be) a strictly technical exercise, a release is something that’s collaboratively decided by the business (representative) and the responsible development team.
However, most features aren’t developed in less than a day, and keeping them on separate branches will result in multiple long-lived feature branches, with all the associated headaches. Feature toggles (or flags or switches) are an answer to that problem.
Feature toggles allow a team to deploy the software whenever they feel like it, but “hide” specific functionality until it’s ready for the end user to see. Essentially, a feature toggle is a conditional statement wrapping a piece of functionality. The condition can be based on the value of a cookie, the user agent, the IP address of the user, geolocation, date or time, and many more different variables.
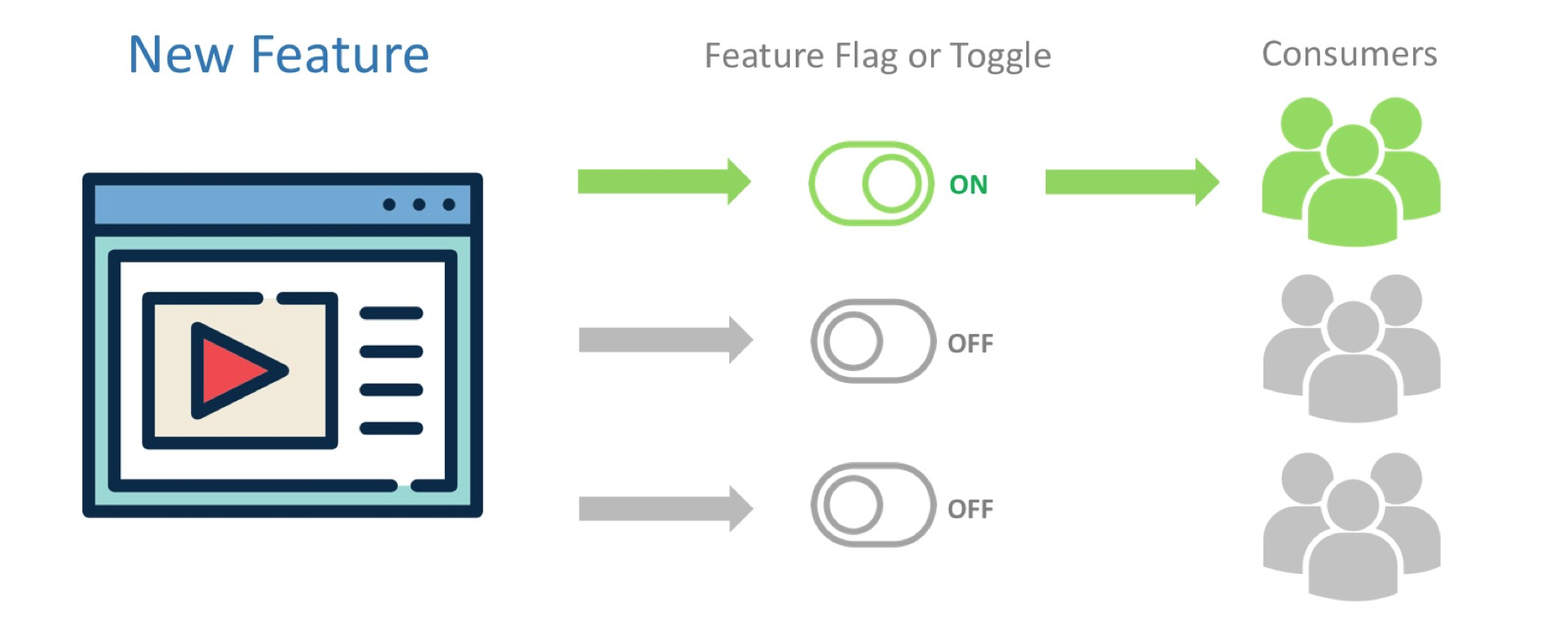
The new version of this particular search page took nearly two months to build. If we hadn’t used a feature toggle on the page, we would have been forced to use a long-lived feature branch, or block deployments for two months, both unacceptable.
Instead, having the feature toggle in place allowed us to continuously deploy this feature (and many other features that were being worked on), while preventing our end-user to see the search page before we deemed it ready.
At some point during development we enabled the toggle for the search page for the internal company network. This allowed us to get some early feedback before we enabled the toggle for a subset of production traffic (we started out at 10% of traffic). Then we started ramping up to 100%, continuously checking our monitoring, (business) metrics and user feedback. Once the feature was completely live for all end-users, the toggle was ready to be removed.
Code reviews & pair programming
A lot of teams probably use branches in some way to conduct code reviews – more than likely using pull or merge requests probably. Whenever I discuss Continuous Deployment and Trunk Based Development, it’s only natural that people ask me how code reviews (and thus branches) fit in the picture.
While I’m not necessarily against pull requests (and have been known to use them) – and using them for code reviews is better than having no reviews at all! – there’s a far more effective way of doing code reviews: pair programming!
Let’s go back to the pull request, in the context of a code review. When developer #1 is done writing their code, they shoot off a pull request, which is then hopefully picked up quickly by developer #2 and reviewed. Unfortunately, developer #2 was probably working on something else, so we have just pulled them out of their context (and flow). After the review, the pull request is sent back to developer #1, potentially with requested changes added. This can go back and forth a few times, depending on the amount of questions and/or changes requested after each subsequent review. Every iteration causes the reviewer and the submitter to be pulled out of their (new) context. This can incur significant flow delay inside a team.
Because of their asynchronous nature, I think pull requests (by their very nature) are a suboptimal way of performing code reviews.
This tweet by Neil Killick sums up my concerns with pull requests well:
Code reviews are generally inferior to pairing & mobbing because:
— Neil Killick (@neil_killick) September 23, 2018
– They introduce flow delay, even in the most collaborative of teams
– Quality resides in the conversations and decisions leading to the code, not the code itself
– You can’t see the why behind the code /not/ there
Instead, if you put those two people together you get continuous and inline code review! For those in highly regulated environments that require it, pair programming automatically ticks the “four-eyes principle” box. There are even tools that allow you to co-sign commits, as you write them.
Pair programming also results in immediate knowledge transfer, from more experienced people to less experienced people, from ops to dev and vice versa, etc.
Pair programming can be tiring however, and should not be enforced, but rather encouraged. The benefits are clear though. Teams that regularly practice pair programming are significantly more productive, produce higher quality software with less defects, and are generally more effective.
Stay tuned for part 3!
Pingback: The Road to Continuous Deployment (part 1) - Michiel Rook's blog
Pingback: The Road to Continuous Deployment (part 3) - Michiel Rook's blog