In 2016 and 2017, I gave a series of talks titled “The Road to Continuous Deployment: a Case Study”, detailing some of the work I did in 2015 together with the team at De Persgroep Employment Solutions. At DPES, we significantly improved time to market, quality and delivery speed by implementing Continuous Delivery. In the talk I explain how the process took us to multiple production releases per day and how we significantly changed and improved our way of working. This blog post reviews a (short) version of that talk, as given during the first online All Day DevOps conference, in 2016.
The post below was previously published by Derek Weeks on the All Day DevOps Blog.
We have all heard the excuses: management won’t go for it; the code is a jumbled mess; it’s too large; too many regulatory hurdles. The trek to Continuous Integration/Continuous Deployment has stumbled for many enterprises, but many more each day have made it.
Michiel Rook spoke at the 2016 All Day DevOps conference about his road to Continuous Deployment. He used an example he worked on for De Persgroep Employment Solutions, which operates a number of job portals. This specific project was called the San Diego Project, but it was known internally as the Big Ball of Mud because the code base was such a mess. The image below diagrams the legacy system – the beginning of the road.
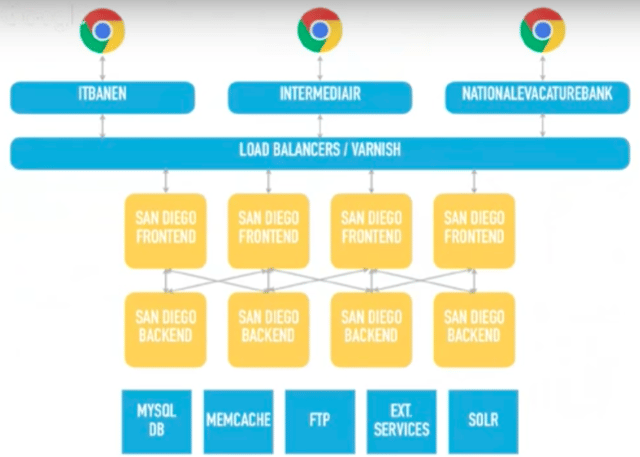
The project was burdened with: infrequent, manual releases, fragile tests, frequent outages and issues, a frustrated team of about 16 people, and low-confidence modifying existing code. Sound familiar? Yep, you were not alone.
The team knew something needed to be done, so they set some goals, including:
- Reduce issues
- Reduce cycle time
- Increase productivity
- Increase motivation
Their approach was to take the monolith, build a proxy and add a service, and then keep adding services until the monolith can be thrown away.
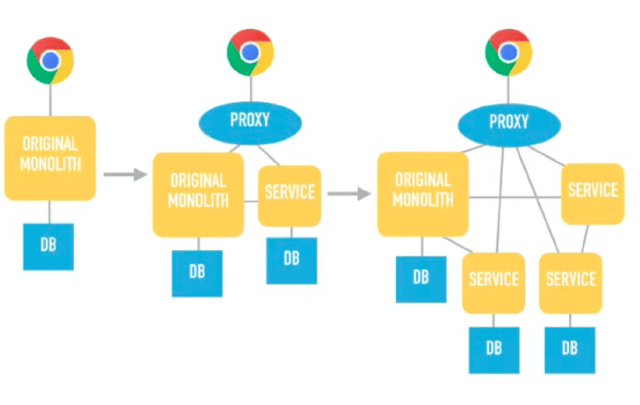
Of course, this is a simple explanation; much more went into the trek.
So, in this article, we are going to dig deeper, as Michiel also does in his full talk.
They started with a foundation of principles to guide their journey:
- Apply the strangler pattern
- Use API first methodology
- Set one service per domain object (job, jobseeker, etc.)
- Migrate individual pages
- Establish services behind load balancers
- Access legacy databases
- Implement continuous deployment
- Utilize Docker containers
- Develop frontends as services
This all culminates to continuously deliver value, something Michiel calls “Continuous Everything.”
It starts with Continuous Integration: developing and building/testing, resulting in an artifact each time. Then, Continuous Delivery: building/testing–>acceptance–>production; going into production is a manual process, but the code is always deployable. Finally, you reach Continuous Deployment when the whole process is automated.
Continuous Deployment is advantageous because it offers the following:
- Small steps
- Early feedback
- Reduce cycle time
- Reduce risk
- Room to experiment

Now that Michiel’s project is behind him, he offered the following key aspects of any road trip to continuous deployment:
Only Commit to Master. No branches. You don’t want to delay integration and abuse version control for functional separation. Plus, everything on a branch increases the risk of conflicts and delays integration.
Every Commit Goes to Production.
Use pair programming for code review. This will require discipline, but all development needs to be paired. Mix and match experienced developers.
Quality Gates. Ensure a substantial amount of tests and code coverage.
Feature Toggles and A/B Tests. Determine which version people can/can’t see and facilitate A/B testing. But, be sure to keep the number in check.
Dashboards. Display is essential for deployments. Measure everything: KPIs, build times, page load times, number of visitors, results of A/B tests, etc.
DevOps. Mentality is a culture; no more walls between dev and ops. Ownership lies within the team for everything, but this doesn’t mean everyone knows everything.
Automate Repeatable Things. If you need to do something twice, you have done it too many times.
Continuous Testing. Use unit tests and smoke tests to see if a service is live, and always monitor. Exploratory testing is important because you continue to test the most critical paths.
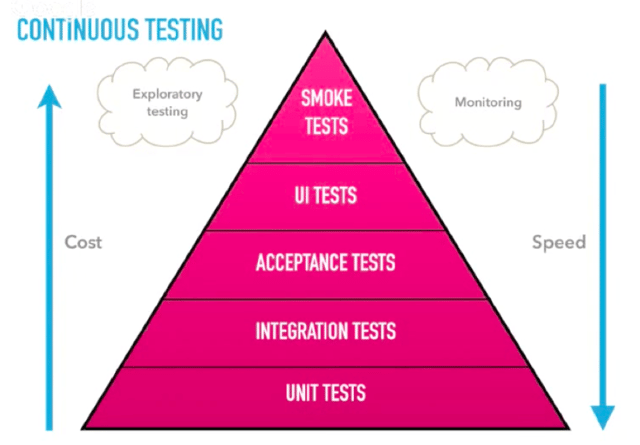
Pipeline as Code. Automate the pipeline.
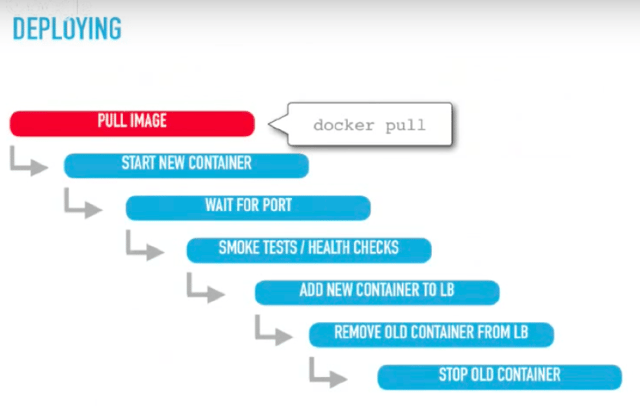
In the end, the deployment looks like this.
Feedback – DevOps is built on the importance of feedback. One example Michiel had on this project was a large, red flashing light that signaled a build failure. Whenever it went off, that became the number one thing people started working on.
Michiel’s project spanned over one year. In the end, they reduced the total build time per service to less than 10 minutes, significantly improved page load times, increased confidence and velocity, and more. The universal truths of the importance of team acceptance and that change is hard were seen. They also learned, among other things, that the alignment with business priorities is key, ensuring you have the necessary experience on staff is essential, and limiting feature toggles is crucial.
Overall, Michiel and his team made it to Continuous Deployment. At the end of his talk, Michiel did report that, to his dismay, the legacy system they are seeking to replace is also still in service. The road is long, but worth the trip.